
TLDR
Nico Druelle and The Revenue Architects (TRA) built a programmatic TAM that updates, scores, and routes accounts as the market changes. Three independent crons run against one Supabase warehouse: accounts refresh weekly, signals land daily, and scoring recomputes overnight. Claude Code acts as the operator interface, so ops teams can ask plain English questions against the same scripts the system already runs.
About Nico
Nico Druelle is the Founder of The Revenue Architects, a GTM engineering studio that designs revenue decision systems for Series B+ B2B companies like Canva, Linear, WorkOS, and Braintrust. He helps top GTM teams move beyond automation volume toward versioned, agent-orchestrated revenue architecture, and has been building much of TRA itself on Claude Code.
True story: Nico met Nathan after commenting on a LinkedIn post with one line: “If you can scale beyond 50,000 rows per table, let’s talk.” A coffee on the Freckle rooftop followed.
The problem
A TAM starts going stale as soon as it gets formalized.
The list might be right when it is built, but the market keeps moving. Companies raise, hire, launch, pivot, shrink, and change priorities. New accounts enter the ICP. Existing accounts stop matching it. The reps keep working the list because nobody has told them the list stopped being true.
Most TAM projects follow the same pattern. Someone in ops pulls a list from Clay, ZoomInfo, Apollo, or a few custom sources. It gets pushed into Salesforce or a spreadsheet. The team works on it for a few weeks. Then the signals decay, the scoring gets stale, and the TAM quietly turns into a static artifact.

Nico puts numbers around a problem most GTM teams already feel.
- 22 percent of accounts in a 90-day-old TAM are stale.
- 6 weeks is the median time-to-stale for an AI-native ICP.
- 0 is what most teams spend measuring this.
That last number is the real issue. Teams know their TAM gets stale, but they rarely measure how fast it happens or build the system that keeps it current.
If you ask Nico, the TAM should not be treated as a deliverable. Rather, it should be treated as infrastructure. The question is not “what accounts should we go after this quarter?” It is “what system keeps telling us which accounts matter right now?”
Three independent crons

A programmatic TAM has three things moving at all times. Accounts, signals, and scoring.
Nico keeps those jobs separate. They run against the same warehouse, but each cron owns one piece of the system.
Accounts refresh weekly
A discovery agent pulls new accounts from Crunchbase, YC, HuggingFace, Apollo, custom seed lists, and other sources. Each new account fingerprints against the existing core account database. Matches dedupe. Net-new companies enter the TAM, get scored, and join the working set.
The goal is not to rebuild the TAM from scratch, but to keep the list alive as the market changes.
Signals land daily
6 hunter agents sweep for funding, hiring, model releases, papers, GitHub activity, and community activity. At steady state, the system captures roughly 400 signals every 30 days.
Each signal attaches to an account in the warehouse with a timestamp and a source. That matters because a signal without a source is hard to trust.
Scoring and routing recompute overnight
Composite scores update daily. Top accounts push to Slack. READY tier-one accounts auto-enroll in sequences. Leads get created in Salesforce with the right owner.
Each cron runs independently. Accounts can refresh without forcing a scoring run. Signals can land without triggering routing. Scoring can recompute against the latest warehouse state overnight.
That separation is what keeps the system maintainable. Most TAM workflows get brittle when teams try to force discovery, signal capture, scoring, and routing into one giant job. Nico’s model gives each motion a clear owner.
One warehouse, two feeds, three outputs
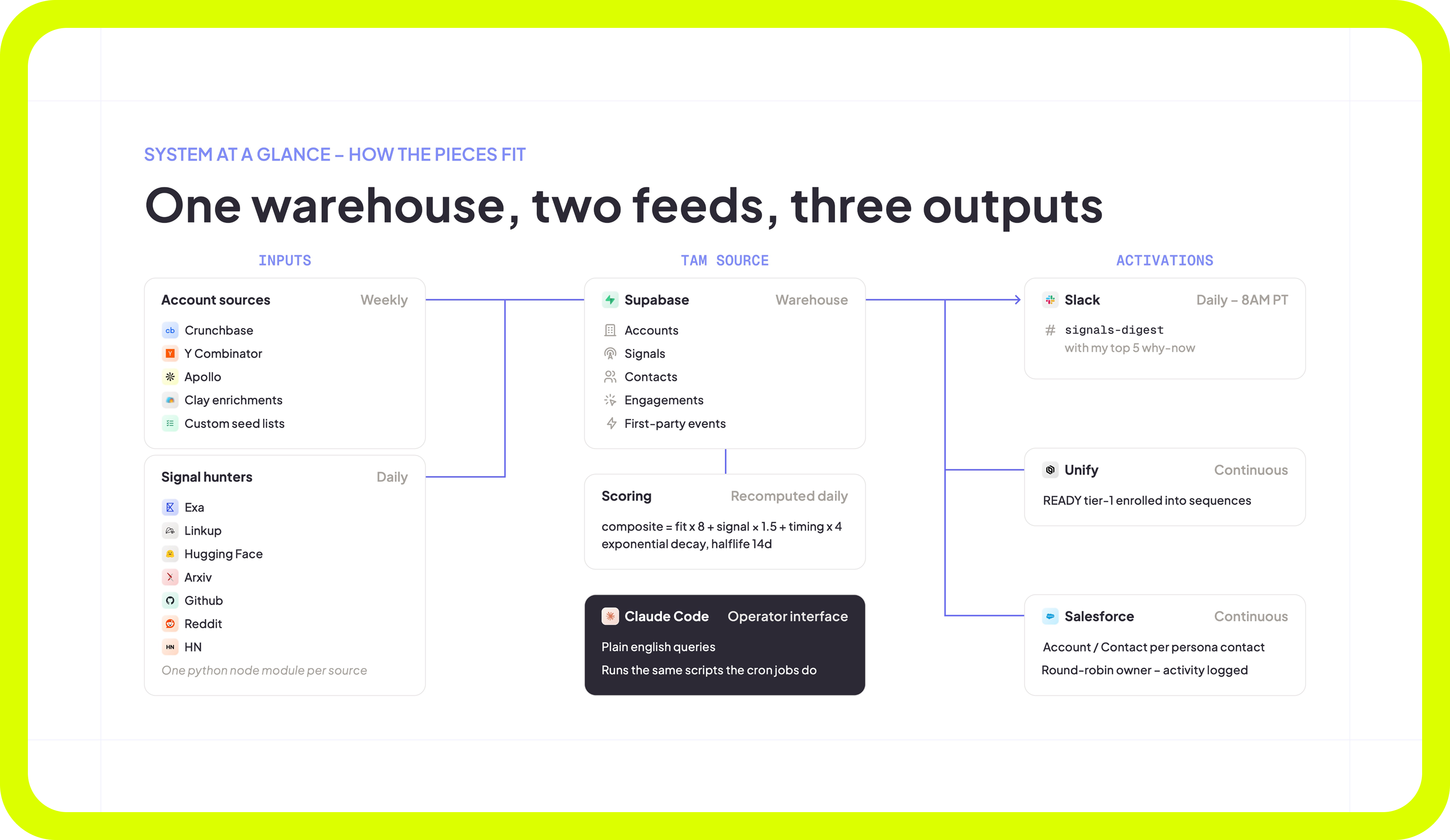
Nico runs the system on Supabase.
Two input streams flow into the warehouse. Account sources run weekly, including Crunchbase, YC, Apollo, Clay enrichments, and custom seed lists. Signal hunters run daily across sources like Exa, Linkup, HuggingFace, Arxiv, GitHub, Reddit, and Hacker News.
Each source is a Python module running on its own schedule. That keeps the system easy to inspect, debug, and extend. If a source breaks, it does not take the whole TAM down with it.
Accounts, signals, contacts, engagements, and first-party events all land in Supabase. First-party data is vital to the success of this flow. Nico’s team at TRA reverse-engineered the API for one of their tracking tools so website visit data could live next to fit and intent data in the same system.
That means the team is not asking one tool for fit, another for signals, and another for engagement history. The query runs across one warehouse.
Scoring is deterministic. The formula is:
composite = fit × 8 + signal × 1.5 + timing × 4
It also uses exponential decay with a 14-day half-life. New signals matter more. Old signals fade. The composite recomputes overnight against the full TAM.

Three outputs activate from the warehouse.
Slack
Every morning at 8 AM PT, the system posts a signal digest with the top five accounts and a one-line “why now.”
Unify
READY tier-one accounts auto-enroll into a five-touch, ten-day sequence.
Salesforce
A lead gets created per persona contact, round-robined to an owner, with activity logged back to the warehouse.
The closed loop is the point. Every engagement, from an opened email to a LinkedIn reply to a booked demo, writes back to Supabase. The next score gets smarter because the system has more context than it had yesterday.
That is the difference between a list and infrastructure. A list gets worse over time. Infrastructure gets better when it runs.
Claude Code as the operator interface

Working this way means the team does not need a dashboard for every new question. Reps and ops teams can ask plain English questions against the same scripts the crons already run, which keeps the interface easier to maintain as the TAM evolves. A new “show me X” question does not require a dashboard ticket, a new BI view, or a detour through three tools. It becomes a query the team can iterate on live.
Questions are dependent on who is asking:
BDR
- Top 20 accounts to go after this week.
- Right contact plus next-best-action for the top five.
- Draft the five-step outbound sequence.
Sales leader
- In-flight accounts with the strongest first-party signals.
- Silent-but-signaling accounts that are warm but unworked.
- Accounts the team should stop working.
GTME
- Top-signal accounts with no rep owner.
- Coverage gaps by segment, source, or persona.
- Pipeline logic that needs to be inspected or adjusted.
That is what makes Claude Code useful here. It is not a separate chat layer sitting next to the system. It is the operator interface for the system itself.
Output reasons, not scores
TRA doesn’t push the composite score into the CRM. They push the reasons behind the score. And, that distinction matters.
A score invites debate. An AE sees a 73 next to an account and the conversation becomes, “why is this a 73 and not an 80?” That is a suboptimal use of a rep’s time.
Reasons lead to more actionable conversations. An account might surface because it is a close fit on stage and headcount, has two strong recent signals, and entered a timing window in the last 14 days. The AE can react to that. They can agree, disagree, or add field context.
The team is no longer arguing with a number. They are inspecting the criteria.
That makes the system easier to trust and easier to improve. If the reasons are wrong, the team can update the signal logic. If the reasons are right and the rep still disagrees, that is useful feedback too.
Q&A
Is the scoring formula proprietary?
The formula is deterministic and visible: fit × 8 + signal × 1.5 + timing × 4. What is proprietary is which signals count and how they get tagged. The logic lives in a skill. We iterate weekly with sales leadership. When they tell us a factor is over- or under-weighted, we update the skill, push the change as a PR so everyone can see it, and the whole TAM re-scores overnight.
Are your BDRs actually running terminal queries?
No. Reps work from chat, Unify, or Salesforce. The terminal interface is for ops and GTM engineers. The rep-facing surfaces are Slack and the platforms they already live in. Claude Code is the back of the house.
What happens when multiple BDRs query the system simultaneously?
This is what we spend the most time on. The hard part is not building the pipelines. The hard part is making sure every edit in the downstream systems writes back to the central system correctly. Setup is easy. Maintenance is the work.
Does this work better for larger TAMs?
Yes. The more accounts, the more noise, and the more value you get from having a system score and rank for you. If your TAM is 200 accounts, you can manage it by hand. At 2,000, you can’t.
Why Supabase instead of Salesforce or a real data warehouse?
For seed through Series B, Supabase is fast, cheap, and lightweight. You own the instance. You can move quickly. Past Series B, when the data team owns the warehouse, you move into the warehouse. We pick the right tool for the stage.
What are the two highest-value Claude Code applications for GTM?
Variant generation and context aggregation.
Variant generation means I can produce ten outbound experiments or ad creatives in the time it used to take to write one, and my job becomes curator.
Context aggregation means agents can sit on the Slack channels we share with clients and summarize decisions daily. We never have to ask, “why did we create this score six months ago?” because the answer is already in the warehouse.
About Claude Code for GTM
Claude Code for GTM was a private builder session and happy hour hosted at Freckle HQ for operators building real go-to-market workflows in Claude Code.
More than 50 GTM operators came through to see what people are actually building beyond the demo layer: content systems, CRM automation, TAM expansion, and agent-native GTM infrastructure. The useful parts were practical. What worked. What broke. What needed guardrails. What moved from “interesting weekend project” to something an operator could run again on Monday.
The session also previewed where Freckle is headed. We’re rebuilding Freckle to work natively inside Claude Code, so GTM teams can build complex, composable workflows directly from the terminal.
Resources
- The Revenue Architects: the-revenue-architects.com
- View Nico’s full presentation: Deck
Join us next time
We’re going to keep hosting operators who are building real GTM systems with AI, not just talking about them.
Follow the Freckle team on LinkedIn to hear about future events, or reach out to Emily directly at emily@freckle.io.
Good people. Better tools. More to come.





